
Toulouse, le 26 novembre 1982
N° 0148 CT/GEPAN
Groupe d'Etudes des Phénomènes Aérospatiaux Non-identifiés
|
Toulouse, le 26 novembre 1982 |
ISSN : 0750-6694
- LES CAS IDENTIFIES A POSTERIORI
- COMPARAISON IDENTIFIE / NON-IDENTIFIE
ANNEXES 1 : RÈGLES DE CODAGE (VERSION 4)
ANNEXES 2 : RÉPARTITION SELON LE TYPE
ANNEXES 3 : APPROCHE THÉORIQUE
Il est clair. que cette distinction identifié / non-identifié concerne le système : phénomène - conditions d'observation - témoin - expert dans toute sa complexité ; aussi, les conclusions se limiteront à deux points particuliers :
Caractériser les cas non-identifiés ( D ) par rapport aux cas identifiés a posteriori, c'est-à-dire plus simplement déterminer les spécificités les plus générales de ces cas qui ont, en définitive, conduit l'expert à ne pas les rattacher à des phénomènes connus.
Etudier, par des méthodes d'analyses factorielles, la répartition des cas D dans la typologie sommaire et les structures élaborées au paragraphe précédent pour les cas identifiés a posteriori ( A ou B ). Est-ce que ces cas D se rapprochent de certaines identifications, est-ce qu'une ou plusieurs sous-classes homogènes vont se démarquer ?
4.1. - DESCRIPTION SOMMAIRE
On se propose donc de comparer les distributions des observations sur les différentes variables en fonction du type ( A ou B, C et D ). Ceci conduit à la représentation par les histogrammes de l'Annexe 2. Comme c'est essentiellement pour l'usage des analyses factorielles que le codage du paragraphe 2.2. a été élaboré, on conserve dans ce cas particulier le codage brut ( Cf. Annexe 1 ) des variables qui est plus précis sans que cela ne nuise à la robustesse de l'analyse.
L'étude des histogrammes de l'Annexe 2 amène les remarques suivantes :
Pour la plupart des variables les distributions sont relativement homogènes d'un type à l'autre et ce sont les cas D qui sont le plus documentés ( i.e. où les informations non disponibles sont les moins nombreuses ).
Des différences significatives apparaissent pour les distributions de certaines variables :
comparativement moins d'observations de cas D dans les "Hameaux, petits villages" et plus dans les zones dépeuplées ( habitation isolée, désert, haute montagne et utilisation moindre d'instruments ( jumelles, photos... ) ) ;
moins d'observations de cas D de durées brèves ( < 1 mn ) souvent interprétées par la suite comme des rentrées atmosphériques et plus d'observations de durée moyenne ;
la distance est beaucoup plus souvent estimée pour les cas D avec une prépondérance pour l'intervalle 20 m - 1 km ; - absence de bruit plus marquée pour les cas D ;
très nettement plus de hauteurs angulaires estimées nulles ( vu su sol ou "près du sol" ) pour ces mêmes cas D ;
nettement plus d'estimations métriques de la taille entre 2 et 10 m.
Ainsi une observation reste non-identifiée surtout si le phénomène a été perçu par le témoin dans un cadre très "humain" ; i.e. jugé à une distance inférieure au km d'une taille "raisonnable" de 2 à 10 m, souvent proche de l'horizon et pendant une durée moyenne, suffisante pour une observation détaillée mais insuffisante pour la recherche d'indices matériels ( photos avec réseau de diffraction, mesures physiques... ).
4.2. - REPRÉSENTATIONS FACTORIELLES
On reprend donc les mêmes méthodes que celles utilisées au paragraphe 3.3.. La population est cette fois l'ensemble des cas A, B et D ; les cas C ont été volontairement éliminés afin de limiter la confusion déjà importante entre les divers types de cas. Ce sont toujours les mêmes variables ( durée, taille, distance, luminosité, vitesse, hauteur angulaire ) codées comme au paragraphe 3.3. qui sont considérées comme variables actives.
A une rotation près, on retrouve dans la troisième planche la même représentation que dans la planche 1. Celle-ci amène donc les mêmes commentaires en remarquant que, cette fois, c'est le premier axe qui prend en compte les liaisons entre les variables : estimation de la distance, de la hauteur angulaire, de la taille tandis que le deuxième axe est lié à la durée de l'observation. La présence des cas D dans l'analyse ne modifie donc en rien les "structures" des variables qui peuvent être interprétées en un certain sens ( 1 ) comme les caractéristiques des descriptions de phénomènes non-identifiés pour le témoin et que ceux-ci soient identifiés ou non a posteriori. La présence des cas D ne fait qu'accroître ( axe de plus grande inertie ) la distinction entre, d'une part, les phénomènes jugés dans le cadre de référence du témoin ( vu au sol, distance en mètres, taille non ponctuelle ) et d'autre part la classe de confusions avec des phénomènes astronomiques.
(1) Ces "caractéristiques" sont à approfondir sur le plan expérimental de la psychologie de la perception à l'aide d'outils statistiques décisionnels et non plus seulement descriptifs.
Le calcul analogue à celui effectué pour la planche 2 et concernant les autres modalités n'appelle pas de remarques complémentaires.
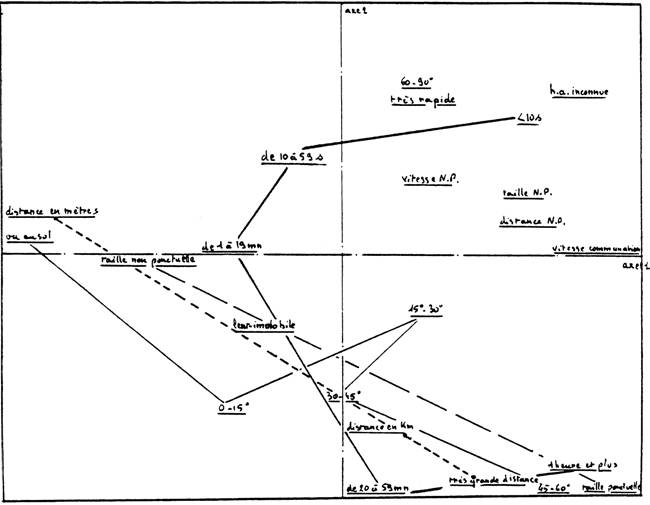
Planche 3
4.3. - REPRÉSENTATIONS DES OBSERVATIONS ( PLANCHE 4 )
On cherche maintenant à situer les cas D par rapport aux classes des cas identifiés. Pour ceci, il suffit de reprendre le plan factoriel des planches 1 et 2 et d'y projeter les observations au lieu des modalités des variables. Les cas identifiés qui participent à l'analyse ( i.e. au calcul des axes d'inertie du nuage ) sont codés de 2 à M tandis que les cas non-identifiés, codés par des "1" sont considérés de poids nul et ainsi n'interviennent pas dans la représentation. Ceci permet donc de comparer les cas non identifiés non pas à la réalité des phénomènes connus mais bien à la réalité de témoignages de ces phénomènes avec toutes les déformations dont il faut bien tenir compte pour rendre les comparaisons possibles.
Parmi les cas identifiés, on retrouve bien les trois axes de dispersions conformément à ceux notés précédemment et sur lesquels est projetée la diaspora des cas non-identifiés. On remarque que les sources de confusions possibles donnent des représentations très enchevêtrées, pas du tout disjointes les unes des autres, montrant ainsi que, témoignage, expertise et codage entraînent de très grosses pertes d'informations ( i.e. un accroissement de l'entropie ) ; de la vingtaine de classes de la typologie initiale ( avant témoignage ), il n'en subsiste que trois et peu distinctes les unes des autres.
La projection des cas non-identifiés n'amène en apparence pas de classe nouvelle. Ils se répartissent selon les trois classes ou axes de dispersion déjà existants mais avec une préférence très marquée pour le quart en haut à gauche. Ceci laisserait donc penser, qu'à l'exception des cas non-identifiés qui sont ( ou se comportent comme ) des confusions astronomiques, les autres sont à rattacher à l'ensemble* des "confusions hétéroclites". Ceci ne signifiant pas que tous les cas D sont des confusions de même type mais plutôt qu'ils seraient à rattacher à un rassemblement de cas particuliers en marge des confusions les plus fréquentes. Mais il faut relativiser cette dernière remarque en rappelant que la population étudiée n'est pas celle des phénomènes mais celles de comportements de témoins variés dans des conditions diverses. De plus, l'une des variables prépondérantes pour caractériser la troisième classe est l'estimation de la distance ( distance en mètres ) et comme le note JIMENEZ - 82 lors de l'étude de cas à témoignages multiples ( rentrée de satellites avec plus de 40 observations par exemple ) "ces estimations sont toujours fausses par rapport à la réalité du phénomène : il s'agit toujours de sous estimation traduisant un rapprochement subjectif très prononcé du phénomène".
* Il s'agit là d'un ensemble et non pas d'une classe bien définie.
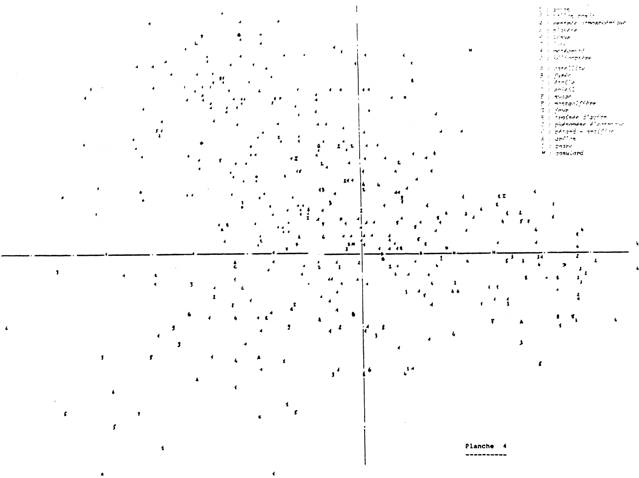
Planche 4
La complexité de l'objet de l'étude alliée au manque de fiabilité des informations rendent les études statistiques très délicates. La classification obtenue au paragraphe 3 faisant apparaître principalement 3 groupes :
reflète bien les difficultés rencontrées. De la typologie initiale des phénomènes supposés à l'origine des observations, il ne subsiste que quelques classes mal distinctes concernant le comportement du système "phénomène/témoin/situation/expert" et non plus seulement les phénomènes.
En ajoutant les cas non-identifiés ( § 4 ), ces difficultés ne font que s'accroître car la variable "estimation de la distance", paramètre le plus subjectif, prend une place prépondérante.
En l'état actuel des choses, c'est-à-dire tant qu'il reste impossible de produire une typologie fiable, le plus prudent, à l'exception des cas relevant de confusions banales ( planète, rentrée atmosphérique ) est de considérer chaque cas comme un cas particulier à traiter individuellement.
6.1. – PROBLÈMES
Les problèmes rencontrés lors de cette étude sont de deux ordres :
La réponse au premier nécessiterait d'une part une action auprès de la Gendarmerie Nationale en vue de donner aux procès-verbaux une forme plus adaptée, et peut-être même une action auprès du public ( i.e. auprès des témoins potentiels ) et, d'autre part, un codage exhaustif de ces procès-verbaux.
Il ne s'agit donc plus de faire rentrer un procès-verbal dans un moule ( le codage ) mais bien de prendre en compte le maximum d'informations en respectant la forme employée par le témoin. On est donc conduit à relever, pour chaque procès-verbal, tous les mot-clés en clair tels que les a cités le témoin * sans faire de regroupement a priori. Ce n'est qu'a posteriori et selon les besoins d'une analyse qu'il sera possible d'établir des tableaux de synonymes afin de permettre la comparaison des procès-verbaux. Cette démarche nécessite des outils informatiques plus sophistiqués que ceux utilisés jusqu'alors et donc évidemment plus coûteux.
Une réponse théorique est proposée ci-dessous pour aborder le deuxième problème.
* Cette gestion des procès-verbaux est en cours de mise en place.
6.2. - MODÈLE THÉORIQUE
La situation est la suivante :
Un phénomène, dont les caractéristiques sont représentées par une variable aléatoire multidimensionnelle Y ( forme, couleur, luminosité... ), est observé par un témoin qui en fait une description à l'aide d'une variable de même type X. Que peut-on dire des valeurs prises par Y connaissant X ?
Concernant un phénomène isolé, il n'y a pas de solution mais si on se place au niveau d'un ensemble ( une population ) d'observations, ce qui importe ce ne sont plus les caractéristiques d'un phénomène mais leurs fréquences d'apparition ou encore la loi de probabilité de Y ( par exemple : nombre de phénomènes rouges ou probabilité qu'un phénomène soit rouge ).
Dans ce cas, connaissant ( ou sachant estimer ) la loi de probabilité de X ( par exemple : probabilité pour que le témoignage relate un phénomène rouge ) et la loi conditionnelle de Y à X ( par exemple : probabilité que Y soit rouge sachant que X le décrit vert ou bleu ou rouge... ) alors la loi de Y peut être estimée.
Ainsi, dans ce cadre théorique idéal, les analyses factorielles calculées comme aux paragraphes 3 et 4 et les classifications ne concerneront plus les témoignages mais décriront bien la population des phénomènes étudiés ( pour plus de détails, cf. BESSE-VIDAL - 82 ou encore l'annexe 3 ).
En pratique, l'estimation de la loi conditionnelle de Y à X pose de gros problèmes et nécessite de nombreuses expériences avant d'être opérationnelle surtout lorsque, comme c'est le cas pour les variables hauteur angulaire, distance, taille, les erreurs d'estimations ne sont pas indépendantes. ( Cf. Annexe 3 ). Mais, au minimum, cette démarche permet de pondérer les variables en fonction de leur fiabilité. Dans le cas de la distance, par exemple, la probabilité qu'un phénomène soit en réalité très éloigné ( distance astronomique ) alors qu'il a été estimé proche ( quelques centaines de mètres ) est loin d'être négligeable ( cf. les cas de rentrée de satellite in JIMENEZ - 82 ). La dispersion artificielle introduite par cette variable sera alors très sensiblement atténuée comparativement aux variables qui, à l'expérience, se montreront plus fiables.
6.3. – STRATÉGIE
L'approche proposée nécessité alors trois étapes :
estimation de la loi conditionnelle par des expériences en laboratoire et à l'aide des cas d'observations multiples où, d'une part, les caractéristiques réelles du phénomène sont connues, et, d'autre part, de nombreux témoignages permettent de faire des estimations ;
test ou qualification de ces estimations en les appliquant à l'étude des cas identifiés a posteriori. Si les résultats obtenus sont insuffisants ( mauvaise classification par exemple ), il faut affiner l'étape précédente sinon :
application à l'étude des cas non-identifiés.
6.4. – CONCLUSION
Il est clair que les outils statistiques classiques ne sont guère adaptés à l'étude de phénomènes rares et non reproductibles pour laquelle ils n'ont pas été conçus.
L'approche proposée dans ce paragraphe devrait permettre de remédier à certains des problèmes rencontrés mais celle-ci sera évidemment longue et coûteuse ; c'est le prix à payer si l'on veut espérer limiter l'accroissement de l'entropie observé tout au long du cheminement de l'information.
BESSE Ph. - 1980
Etude comparative de résultats statistiques élémentaires
CNES/GEPAN
Note Technique n° 2
Avril 1980
BESSE Ph. - 1981
Recherche statistique d'une typologie des descriptions de phénomènes aérospatiaux non-identifiés
CNES/GEPAN
Note Technique n° 4
Mars 1981
BESSE Ph., ESTERLE A., JIMENEZ M. - 1981
Eléments d'une méthodologie de recherche
CNES/GEPAN
Note Technique n° 3
Avril 1981
DUVAL P. - 1979
Règles de codage (4ème version)
CNES/GEPAN
Note Technique n° 1
Octobre 1979
ESTERLE A. - 1981
Le problème des phénomènes aérospatiaux non-identifiés
CNES/GEPAN
Note Technique n° 3
Avril 1981
JIMENEZ M. - 1982
Quelques expériences en psychologie de la perception
CNES/GEPAN
(A paraître)
SESSE Ph. - VIDAL cl. - 1982
Analyse des correspondances et codage par une probabilité de transition.
Statistique et analyse des données - décembre 1982 -
RÈGLES DE CODAGE ( VERSION 4 ) (cf. N. T. n° 1)
© CNES